|
|
 发表于 2008-1-12 15:42:19
|
显示全部楼层
发表于 2008-1-12 15:42:19
|
显示全部楼层
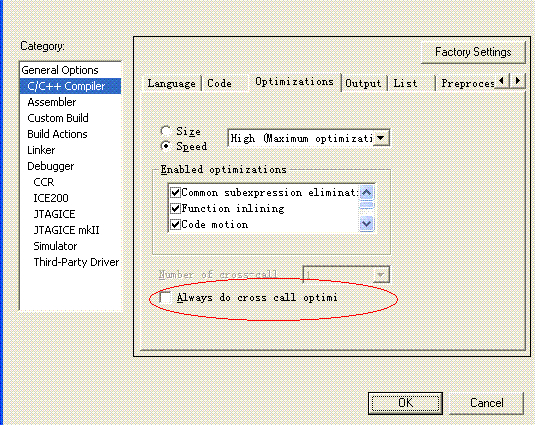
用IAR一直都是最大优化,没出过什么,今天用WDT时出现问题,大家是怎么解决的?先贴出问题
程序初始话时:
WDTCSR |= (1<<WDCE | 1<<WDE);
WDTCSR = (1<<WDE | 1<<WDP2 | 1<<WDP0); // 0.5S
睡眠时:
WDTCSR |= (1<<WDCE | 1<<WDE);
WDTCSR = 0;
查看汇编时发现:IAR优化时吧第一行给搞了个子程序:
1.对应初始化
// 432 WDTCSR |= (1<<WDCE | 1<<WDE);
RCALL ?Subroutine21
// 433 WDTCSR = (1<<WDE | 1<<WDP2 | 1<<WDP0); // 0.5S
??CrossCallReturnLabel_65:
LDI R16, 13
STS 96, R16
2.对应关WDT:
// 693 WDTCSR |= (1<<WDCE | 1<<WDE);
RCALL ?Subroutine21
// 694 WDTCSR = 0;
??CrossCallReturnLabel_66:
LDI R16, 0
STS 96, R16
3.子程序:
?Subroutine21:
LDS R16, 96
ORI R16, 0x18
STS 96, R16
RET
搞个单独的涵数然后关闭优化可以吗? |
|


 楼主
楼主