|
|
 发表于 2011-12-24 10:54:10
|
显示全部楼层
发表于 2011-12-24 10:54:10
|
显示全部楼层
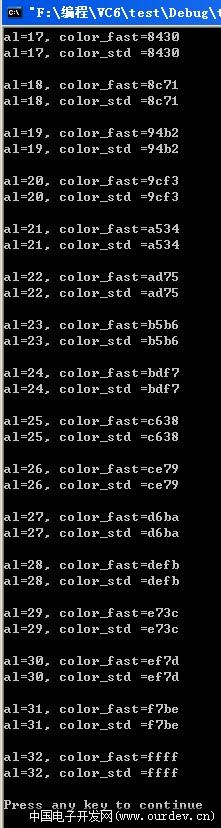
综合28L,29L所述,我在12L提供的快速算法,并不存在杯具一说....只是个别情况略有误差,绝对不影响显示
事实上,标准算法也是有误差的,除非你用浮点来算,再加上四舍五入变成整型,但这样开销太大...
我在PC上使用浮点计算了一遍,结果见后面,
可以看出,在al=25,26,27时, 快速算法反而和浮点标准算法得出的结果一致,
在29L,标准算法得出的结果反而有了误差...
=========================================
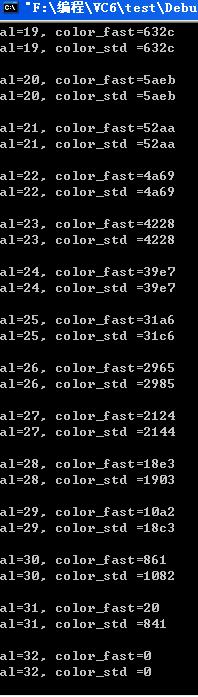
al=24, color_fast=39e7
al=24, color_std =39e7
al=25, color_fast=31a6
al=25, color_std =31a6
al=26, color_fast=2965
al=26, color_std =2965
al=27, color_fast=2124
al=27, color_std =2124
al=28, color_fast=18e3
al=28, color_std =1903
al=29, color_fast=10a2
al=29, color_std =10c2
al=30, color_fast=861
al=30, color_std =1082
al=31, color_fast=20
al=31, color_std =841
al=32, color_fast=0
al=32, color_std=0
=========================================
附浮点算法:
u16 make_alpha16_std(u16 c1, u16 c2, u8 al)
{
u8 r1,g1,b1;
u8 r2,g2,b2;
r1 = (c1>>11<<3);
g1 = (c1>>5<<2);
b1 = (c1<<3);
//
r2 = (c2>>11<<3);
g2 = (c2>>5<<2);
b2 = (c2<<3);
//
r2 = (u8)(r2*al/32.0f + r1*(32-al)/32.0f + 0.5f);
g2 = (u8)(g2*al/32.0f + g1*(32-al)/32.0f + 0.5f);
b2 = (u8)(b2*al/32.0f + b1*(32-al)/32.0f + 0.5f);
return RGB(r2,g2,b2);
} |
|


 楼主
楼主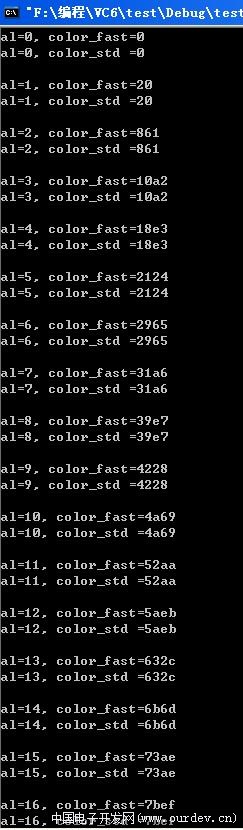
 mark
mark