|
|

楼主 |
发表于 2011-9-27 00:21:59
|
显示全部楼层
上班之后工作很忙,有三个多月没来ourdev了,谢谢楼上的各位的回答。不过好像没人正面回答这个问题。
To chinaye1兄,
谢谢chinaye1兄的回复。
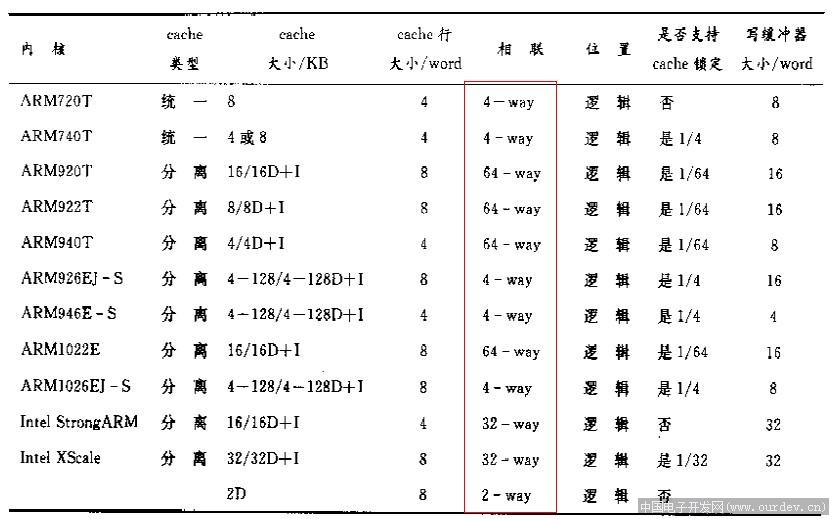
现在PC的处理器早就不是大学教材上的386架构,实质上是CISC和RISC的融合,吸收了很多RISC的优点,一级cache是分离的,下面是core i7移动处理器spec上面摘下来的:
Processor Feature Details
Four or two execution cores
*A 32-KB instruction and 32-KB data first-level cache (L1) for each core
*A 256-KB shared instruction/data second-level cache (L2) for each core
*Up to 8-MB shared instruction/data third-level cache (L3), shared among all cores
“如果把组分得很大,把全部Cache Line都分到一个组里面去,就变成了全相联Cache;
如果把组分得很小,每组只有一个Cache Line,就变成了直接映射Cache
全相连cache查找慢但是命中率高
直接映射cache查找快但是命中率低
n路组组相连cache是二者的折中”
我的问题就是这种折中的数据是基于什么因素来考虑的?都是折中,有的cpu选择了2而有的选择了64,问题就来了选择4(少)和64(多)是基于什么因素的权衡考虑?
To goooogleman兄,
谢谢goooogleman兄的回复。
正如chinaye1兄所说的,在问这个问题的时候我已经查过《ARM嵌入式系统开发:软件设计与优化》这本书了,里面没有提到cache line的权衡问题。
To learner123兄,
谢谢learner123兄的回复。
计算机组成原理没有讲的这么深入的吧?ARM内核确实架构上比CISC要简单,不过,我觉得cpu core和cache可以看成是两个系统的,cpu core的简单与否和cache没有关系。
cache的查找是通过CAM进行的,不是简答的循环比较,这个我在1楼上已经说过了。
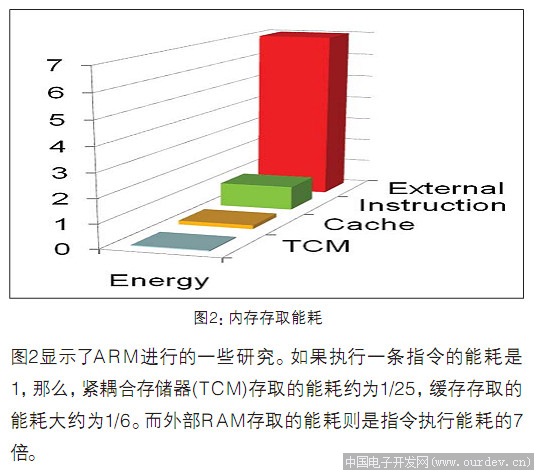
cache的优化有时候是比较重要的,如果算法不幸的遇到cache颠簸,性能会严重受到影响,我是遇到过相关的问题之后才想要弄明白cache的实现细节,在看资料时遇到这个问题,在网上搜了很多中文英文的资料,一直没有找到确切的答案。 |
|


 发表于 2011-6-1 22:14:18
发表于 2011-6-1 22:14:18