|
|
 发表于 2009-10-10 16:59:21
|
显示全部楼层
发表于 2009-10-10 16:59:21
|
显示全部楼层
转一段网上的文章,或许对你有用:
================
英文版长文件名实现
================
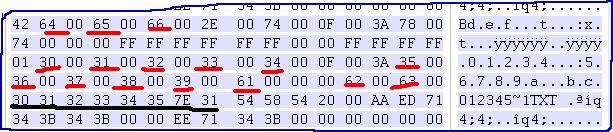
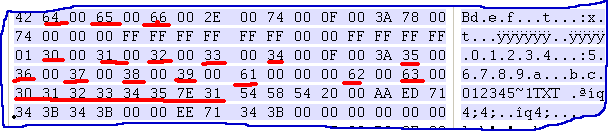
先用实例说明:在CF卡上保存一个名为“longname12345678901234567890.txt”的英文长文件名文件,用WinHEX读
取盘片目录扇区,得到如下数据:
0 1 2 3 4 5 6 7 8 9 A B C D E F
------------------------------------------------
43 39 00 30 00 2E 00 74 00 78 00 0F 00 F4 74 00 | C9.0...t.x...魌.
00 00 FF FF FF FF FF FF FF FF 00 00 FF FF FF FF | ..
02 36 00 37 00 38 00 39 00 30 00 0F 00 F4 31 00 | .6.7.8.9.0...?..
32 00 33 00 34 00 35 00 36 00 00 00 37 00 38 00 | 2.3.4.5.6...7.8.
01 6C 00 6F 00 6E 00 67 00 6E 00 0F 00 F4 61 00 | .l.o.n.g.n...鬭.
6D 00 65 00 31 00 32 00 33 00 00 00 34 00 35 00 | m.e.1.2.3...4.5.
4C 4F 4E 47 4E 41 7E 31 54 58 54 20 00 07 D6 99 | LONGNA~1TXT ..謾
58 39 58 39 00 00 D7 99 58 39 00 00 00 00 00 00 | X9X9..讬X9......
你会发现长文件名是倒着排放的(每目录项存13个字节文件名),最下面是短文件名LONGNA~1TXT
FAT32的一个重要的特点是完全支持长文件名。长文件名依然是记录在目录项中的。为了低版本的OS或程序能正确
读取长文件名文件,系统自动为所有长文件名文件创建了一个对应的短文件名,使对应数据既可以用长文件名寻址,
也可以用短文件名寻址。不支持长文件名的OS或程序会忽略它认为不合法的长文件名字段,而支持长文件名的OS或
程序则会以长文件名为显式项来记录和编辑,并隐藏起短文件名。
当创建一个长文件名文件时,系统会自动加上对应的短文件名,其一般有的原则:
(1)、取长文件名的前6个字符加上"~1"形成短文件名,扩展名不变。
(2)、如果已存在这个文件名,则符号"~"后的数字递增,直到5。
(3)、如果文件名中"~"后面的数字达到5,则短文件名只使用长文件名的前两个字母。通过数学操纵长文件名的剩
余字母生成短文件名的后四个字母,然后加后缀"~1"直到最后(如果有必要,或是其他数字以避免重复的文件名)。
(4)、如果存在老OS或程序无法读取的字符,换以"_"
长文件名的实现有赖于目录项偏移为0xB的属性字节,当此字节的属性为:只读、隐藏、系统、卷标,即其值为0FH
时,DOS和WIN32会认为其不合法而忽略其存在。这正是长文件名存在的依据。将目录项的0xB置为0F,其他就任由
系统定义了,Windows9x或Windows 2000、XP通常支持不超过255个字符的长文件名。系统将长文件名以13个字符为
单位进行切割,每一组占据一个目录项。所以可能一个文件需要多个目录项,这时长文件名的各个目录项按倒序排
列在目录表中,以防与其他文件名混淆。长文件名中的字符采用unicode形式编码,每个字符占据2字节的空间。
系统在存储长文件名时,总是先按倒序填充长文件名目录项,然后紧跟其对应的短文件名。从表2可以看出,长文件
名中并不存储对应文件的文件开始簇、文件大小、各种时间和日期属性。文件的这些属性还是存放在短文件名目录项
中,一个长文件名总是和其相应的短文件名一一对应,短文件名没有了长文件名还可以读,但长文件名如果没有对应
的短文件名,不管什么系统都将忽略其存在。所以短文件名是至关重要的。在不支持长文件名的环境中对短文件名中
的文件名和扩展名字段作更改(包括删除,因为删除是对首字符改写E5H),都会使长文件名形同虚设。长文件名和短
文件名之间的联系光靠他们之间的位置关系维系显然远远不够。其实,长文件名的0xD字节的校验和起很重要的作用,
此校验和是用短文件名的11个字符通过一种运算方式来得到的。系统根据相应的算法来确定相应的长文件名和短文件
名是否匹配。这个算法不太容易用公式说明,我们用一段c程序来加以说明。
假设文件名11个字符组成字符串shortname[],校验和用chknum表示。得到过程如下:
int i,j,chknum=0;
for (i=11; i>0; i--)
chksum = ((chksum & 1) ? 0x80 : 0) + (chksum >> 1) + shortname[j++];
如果通过短文件名计算出来的校验和与长文件名中的0xD偏移处数据不相等。系统无论如何都不会将它们配对的。
-----------------------------------------------------
| 表1 FAT32短文件目录项32个字节的表示定义 |
-----------------------------------------------------
|字节偏移(16进制) | 字节数 | 定义 |
-----------------------------------------------------
| 0x0~0x7 | 8 | 文件名 |
-----------------------------------------------------
| 0x8~0xA | 3 | 扩展名 |
-----------------------------------------------------
| | | | 00000000(读写) |
| | | | 00000001(只读) |
| | | 属| 00000010(隐藏) |
| 0xB* | 1 | 性| 00000100(系统) |
| | | 字| 00001000(卷标) |
| | | 节| 00010000(子目录) |
| | | | 00100000(归档) |
-----------------------------------------------------
| 0xC | 1 | 系统保留 |
-----------------------------------------------------
| 0xD | 1 | 创建时间的10毫秒位 |
-----------------------------------------------------
| 0xE~0xF | 2 | 文件创建时间 |
-----------------------------------------------------
| 0x10~0x11 | 2 | 文件创建日期 |
| 0x12~0x13 | 2 | 文件最后访问日期 |
| 0x14~0x15 | 2 | 文件起始簇号的高16位 |
| 0x16~0x17 | 2 | 文件的最近修改时间 |
| 0x18~0x19 | 2 | 文件的最近修改日期 |
| 0x1A~0x1B | 2 | 文件起始簇号的低16位 |
| 0x1C~0x1F | 4 | 表示文件的长度 |
-----------------------------------------------------
*此字段在短文件目录项中不可取值0FH,如果设值为0FH,目录段为长文件名目录段
------------------------------------------------------
| 表2 FAT32长文件目录项32个字节的表示定义 |
------------------------------------------------------
| 字节偏移 | 字节数| 定义 |
| (16进制) | | |
------------------------------------------------------
| | | | 7 保留未用 |
| | | 属| 6 1表示长文件最后一个目录项|
| | | 性| 5 保留未用 |
| | | 字| 4 |
| 0x0 | 1 | 节| 3 |
| | | 位| 2 顺序号数值 |
| | | 意| 1 |
| | | 义| 0 |
------------------------------------------------------
| 0x1~0xA | 10 | 长文件名unicode码 |
| 0xB | 1 | 长文件名目录项标志,取值0FH |
| 0xC | 1 | 系统保留 |
| 0xD | 1 | 校验值(根据短文件名计算得出) |
| 0xE~0x19 | 12 | 长文件名unicode码 |
| 0x1A~0x1B | 2 | 文件起始簇号(目前常置0) |
| 0x1C~0x1F | 4 | 长文件名unicode码 |
------------------------------------------------------
只要按照上述格式保存长文件名目录项,就可以实现长文件名了,需要修改的部分是打开、删除、改名等文件
系统函数。先生成若干 长文件名目录项,倒序排列,计算校验和,填写序号,设置0F标志,UNICODE转换,
设置最后目录项,填充FF结束。然后,按要求生成短文件名目录项。
====================
简体中文版长文件名实现
====================
上面的方法可以实现英文长文件名,但如果想支持简体中文,还需要支持GB和UNICODE互换,ASCII和GB混排。
---------------
GB和UNICODE互换
---------------
UNICODE转GB和GB转UNICODE没什么好办法,一般通过查表法实现。
unsigned short int unigb_table[7446][2]={
0x00a4,0xa1e8,
0x00a7,0xa1ec,
0x00a8,0xa1a7,
0x00b0,0xa1e3,
0x00b1,0xa1c0,
......
0xffe0,0xa1e9,
0xffe1,0xa1ea,
0xffe3,0xa3fe,
0xffe5,0xa3a4,
0xffff,0x0000
};
上面的表格是按UNICODE增序排列的UNICODE编码到GB编码转换对照表。因为该表为顺序表,所以可以采用二分查表法
大大加快查询速度。没办法,这个表就是有点大,如果不需要支持简体中文,最好把它配置裁减掉,以便节省存储空
间。
将上表反过来就可以实现GB编码到UNICODE编码转换对照表gbuni_table[7446][2]。一个小技巧:直接用EXCEL打开
unigb_table数据部分,选择逗号做分割符,交换两列位置,按GB码增序排序,然后再插入两列,输入逗号,拖下去,
产生两列逗号,保存之,再稍加修改即可生成增序排列的GB编码到UNICODE编码转换对照表。
-------------
ASCII和GB混排
-------------
ASCII字符用一个字节表示,GB汉字用两个字节表示,如果ASCII和GB汉字混排,那么如何把两者区分开呢?
先从ASCII说起。ASCII是用来表示英文字符的一种编码规范,每个ASCII字符占用1个字节(8bits),因此,ASCII编
码可以表示的最大字符数是256,其实英文字符并没有那么多,一般只用前128个(最高位为0),其中包括了控制字符、
数字、大小写字母和其他一些符号。而最高位为1的另128个字符被称为“扩展ASCII”,一般用来存放英文的制表符、
部分音标字符等等的一些其他符号,这种字符编码规范显然用来处理英文没有什么问题。(实际上也可以用来处理法
文、德文等一些其他的西欧字符,但是不能和英文通用),但是面对中文、阿拉伯文之类复杂的文字,255个字符显
然不够用。于是,各个国家纷纷制定了自己的文字编码规范,其中中文的文字编码规范叫做“GB2312-80”,它是和
ASCII兼容的一种编码规范,其实就是利用扩展ASCII没有真正标准化这一点,把一个中文字符用两个扩展ASCII字符
来表示。但是这个方法有问题,最大的问题就是,中文文字没有真正属于自己的编码,因为扩展ASCII码虽然没有真
正的标准化,但是PC里的ASCII码还是有一个事实标准的(存放着英文制表符),所以很多软件利用这些符号来画表格。
这样的软件用到中文系统中,这些表格符就会被误认作中文字,破坏版面。而且,统计中英 文混合字符串中的字数,
也是比较复杂的,我们必须判断一个ASCII码是否扩展,以及它的下一个ASCII是否扩展,然后才“猜”那可能是一个
中文字。
在《ecos增值包》里,不需要这么复杂,我们把00-7F之间的字符标识为ASCII字符,大于7F的字符认为是汉字,一次
操作两字节。这样就能将英文和汉字区别出来分别编码了。
--------------
各种字符编码标准
--------------
为了更清楚地了解《ecos增值包》采用的编码标准,建议详细了解以下术语的确切含义:
ASCII
iso8859-1
GB码
GB2312
GB12345-90
GBK
GB18030
BIG5编码
UTF-8
UTF-16(大端、小端)
UCS2、UCS4
==============================
Windows和Linux长文件名编码的不同
==============================
上面说明GB和UNICODE互换时为了简化描述,我们只是笼统地提到UNICODE编码,其实,Windows和Linux采用的UNICODE
编码格式是不同的。
Windows采用UTF-16LE格式,Linux采用UTF-8格式。
为什么不直接使用UNICODE而非要采用两种不同的UTF格式呢?这里面是有历史渊源的。
-------
Windows
-------
首先介绍Windows。
早期的Windows系统,例如Windows 1.0、Windows 2.0、Windows 3.0、 Windows 3.1等系统,是不支持Unicode编
码的,而是使用ANSI编码(即兼容ASCII的任何本地编码)。即使在Windows 9x系列系统中,也不支持Unicode编码,
只是在文件系统中使用UTF-16编码(例如FAT16/FAT32的长文件名),系统核心还是使用ANSI编码。
微软真正开始实现Unicode编码的是Windows NT操作系统。后来的Windows 2000/XP/Vista都是基于Windows NT内
核的。
微软创造Windows NT系统的最初目的是抢占服务器和工作站市场,微软公司从数字设备公司(Digital Equipment
Corporation)雇佣了一批人员来开发这个新系统,其竞争对手为Unix系列操作系统。
由于Windows NT是全新设计的系统,没有历史累赘,一开始就决定使用Unicode编码作为默认编码。于是,NT系统内
核强制一定要使用Unicode编码。那时,Unicode只有一种形式,就是UTF-16,所以Windows的Unicode实现方案是使用
UTF-16。这样就决定NT的内核只能使用一种字符串,就是UTF-16字符串,用C语言来说,就是wchar_t类型的字符串,
每个字符占用2个字节。看过《快快乐乐跟我学WDM驱动》的读者一定知道在WDM驱动里也不使用普通的字符,而是全
都采用UNICODE,原因就在这里,因为驱动相当于内核补丁,而NT内核强制使用UNICODE编码,所以,WDM驱动里也必
须使用UNICODE。呵呵,初次接触WDM驱动的人肯定对字符串操作感觉怪怪的,习惯就好了,而且,越用越能体会到
使用UNICODE的优势。这不,连USB的字符串描述符也强制要求使用UNICODE。Windows里采用的UTF-16更准确地说是小
端UTF-16。UTF-16可看成是UCS-2的父集。在没有辅助平面字符前,UTF-16与UCS-2所指的是同一的意思。但当引入辅
助平面字符后,就只称为UTF-16了。现在若有软件声称自己支援UCS-2编码,那其实是暗指它不能支援辅助平面字符
的委婉语。
文件系统方面,微软扩展了FAT16/32,增加了长文件名功能;还有就是重新设计了NTFS文件系统。FAT16/FAT32在DOS
下,只能使用8+3的文件名长度,使用的是ANSI编码。在Windows下,通过使用多个目录项来实现长文件名,并强制性
地把长文件名的编码设定为Unicode的UTF-16编码,这样有利于国际化。NTFS文件系统专门为NT系统设计,自然也是
使用UTF-16编码。在Windows下编程,最好直接使用Unicode编程,这样可以避免使用ANSI字符串而在不同语系的
Windows系统里产生乱码现象,更因为少了字符串转换这步,可以加快程序运行速度。
-------------
Unix类操作系统
-------------
Unix产生于1969年,那时还没有出现Unicode呢,ASCII编码是那时最完善的编码。那时硬件十分昂贵,就连使用两个
字节来表示一个字符也是不敢想象的。所以Unix系统是使用单字节编码来表示文字字符,其内核并没有强制使用那种
字符编码。也就是说,Unix类的系统中,在内核里,是不会管你字符编码是什么的,也不会管你会不会发生乱码,只
要是以0结尾的字节串,都是有效的字符串。
由于最初Unix的这种设计,以及大量使用了流技术,这导致Unix无法使用UTF-16字符编码,因为UTF-16是双字节的。
Unicode组织后来设计了UTF-8方案,是一种8位的Unicode编码方法。UTF-8的出现使得Unix类系统支持Unicode成为可
能。这样Unix类的系统就不需要进行重新设计,而通过UTF-8来实现Unicode支持。
使用UTF-8的原因:
ASCII转换成UCS-2,在编码前插入一个0x0。用这些编码,会含括一些控制符,比如 " 或 '/',这在UNIX和一些C函
数中,将会产生严重错误。因此可以肯定,UCS-2不适合作为Unicode的外部编码,也因此诞生了UTF-8。
设计UTF-8的理由:
UTF-8的设计有以下的多字符组序列的特质:
单字节字符的最高有效位元永远为0;
多字节序列中的首个字符组的几个最高有效位元决定了序列的长度。最高有效位为110的是2字节序列,而1110的是三
字节序列,如此类推;
多字节序列中其余的字节中的首两个最高有效位元为10。
Linux是一个Unix的复制品,Unix的这种设计也复制到了Linux。
文件系统方面,Unix类系统也没有强制用户使用UTF-8编码,只要是ASCII兼容的字符编码都可以用,这样有好处也有
坏处,好处是系统内核不必理会编码问题,坏处是会造成编码混乱。
在UTF-8发布之前,Linux 用户使用各种不同特定语言的扩展 ASCII,像欧洲用户用 ISO 8859-1 或 ISO 8859-2,希
腊用户使用 ISO 8859-7,俄罗斯用户使用 KOI-8 / ISO 8859-5/CP1251(西里尔字母)。这使得数据交换出现了很多
问题,并且需要为这些编码之间的差异编写应用软件。这种语言支持是不完善的,而且数据交换没有经过测试。Linux
主要的发行商和应用程序开发者正致力于让主要以 UTF-8 格式表示的 Unicode 成为 Linux 中的标准。
Unix类系统的Unicode实现与Windows不同,两者比较如下:
(1)Windows采取的方案是UTF-16,系统在内核里面强制使用UTF-16编码,甚至连文件系统也必须是UTF-16字符编码格
式,应用层可以不需要理会codepage设置而直接使用UTF-16,也可以把ANSI字符串转换为UTF-16字符串再调用内核。
(2)Unix类的系统采取的方案是UTF-8,内核不理会字符编码的具体实现,Unicode的实现是在应用层上实现,主要是
通过libc的locale功能进行实现。必须把locale设置为UTF-8才可以使用。
----------------------------------
《ecos增值包》对不同编码长文件名的支持
----------------------------------
考虑到Windows和Linux都比较流行,所以决定两者都支持。提供静态配置选项,根据实际情况选择,还支持动态加载
字符编码集,动态支持不同系统的盘片。
下面是两个字符集函数表,通过register_nls(nls_table);向系统注册字符集操作函数表,使用时调用
load_nls("charset"); 加载字符集相应操作函数表就可以正确编解码了。
static struct nls_table default_table = {
.charset = "default", //字符集名称
.uni2char = uni2char, //UNICODE解码
.char2uni = char2uni, //UNICODE编码
.charset2lower = charset2lower,
.charset2upper = charset2upper,
};
static struct nls_table table = {
.charset = "utf8",
.uni2char = uni2char,
.char2uni = char2uni,
.charset2lower = identity, /* no conversion */
.charset2upper = identity,
};
==============
测试长文件名组件
==============
1、使用《ecos增值包》,通过EASYARM2200/SMARTARM2200开发板在CF/SD卡上创建长文件名文件,在Windows中打开,
如显示正确,则创建成功。
中英文混排:
fd = open( "长文件名文件演示longname1234567890.txt", O_WRONLY|O_CREAT );
或
纯英文:
fd = open( "longname12345678901234567890.txt", O_WRONLY|O_CREAT );
2、使用Windows在CF/SD卡上创建若干长文件名,通过EASYARM2200/SMARTARM2200开发板列出卡上的目录和文件,
如显示正确,则长文件名解码成功。
列出根目录下目录名和文件名:
listdir( "/", true, -1, &existingdirents ); |
|



 楼主
楼主